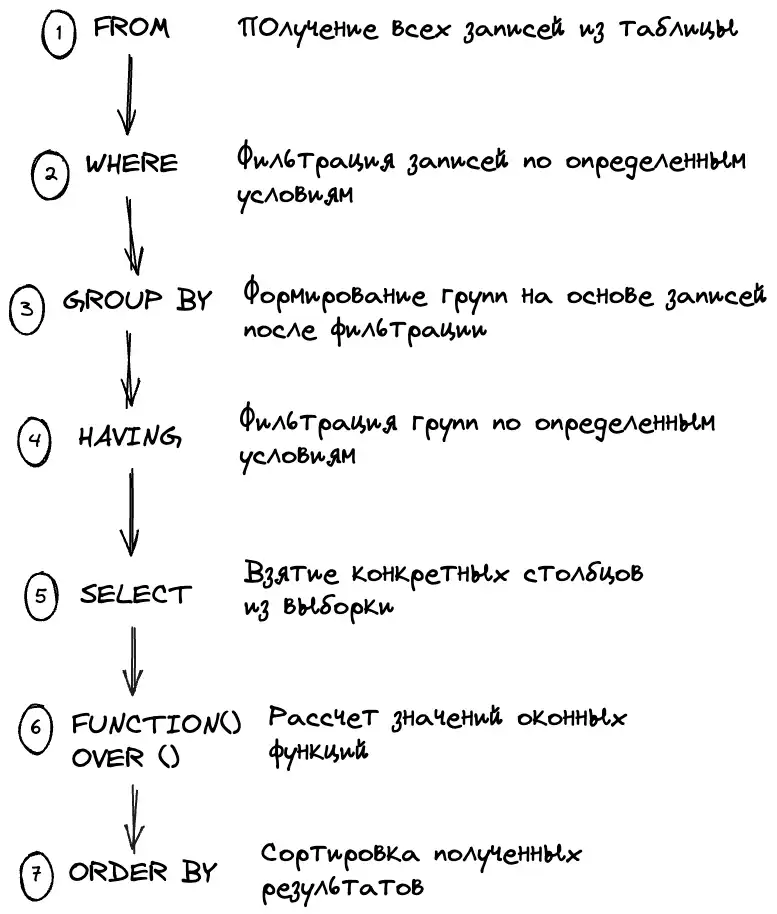
Обобщённое табличное выражение, оператор WITH / CTE (Common Table Expressions)
Обобщённое табличное выражение или CTE (Common Table Expressions) — это временный результирующий набор данных, к которому можно обращаться в последующих запросах.
Выражение с WITH считается «временным», потому что результат не сохраняется где-либо на постоянной основе в схеме базы данных, а действует как временное представление, которое существует только на время выполнения запроса, то есть оно доступно только во время выполнения операторов SELECT, INSERT, UPDATE, DELETE или MERGE. Оно действительно только в том запросе, которому он принадлежит, что позволяет улучшить структуру запроса, не загрязняя глобальное пространство имён.
WITH Aeroflot_trips (aeroflot_plane, town_from, town_to) AS
// после названия идет переименование атрибутов, по желанию
(SELECT plane, town_from, town_to FROM Company
INNER JOIN Trip ON Trip.company = Company.id WHERE name = "Aeroflot")
// сразу после можно писать следующее СТЕ ,
SELECT * FROM Aeroflot_trips;Объединение запросов, оператор Union
UNION по умолчанию убирает повторения в результирующей таблице. Для отображения с повторением есть необязательный параметр ALL.
Для корректной работы UNION нужно, чтобы результирующие таблицы каждого из SQL запросов имели одинаковое число столбцов, с одним и тем же типом данных и в той же самой последовательности.
SELECT DISTINCT Goods.good_name AS name FROM Goods
UNION
SELECT DISTINCT FamilyMembers.member_name AS name FROM FamilyMembers;Условная логика, оператор CASE
SELECT name,
CASE SUBSTRING(name, 1, INSTR(name, ' '))
WHEN 11 THEN "Старшая школа"
WHEN 10 THEN "Старшая школа"
...
ELSE "Начальная школа"
END AS stage
FROM ClassУсловная функция IF
SELECT IF(10 > 20, "TRUE", "FALSE");SELECT id, price,
IF(price >= 150, "Комфорт-класс", "Эконом-класс") AS category
FROM Rooms-- if может быть вложенным
SELECT id, price,
IF(price >= 200, "Бизнес-класс",
IF(price >= 150,
"Комфорт-класс", "Эконом-класс")) AS category
FROM RoomsФункции IFNULL и NULLIF
IFNULL(значение, альтернативное_значение);Функция IFNULL возвращает значение, переданное первым аргументом, если оно не равно NULL, иначе возвращает альтернативное_значение.
NULLIF(значение_1, значение_2);Функция NULLIF возвращает NULL, если значение_1 равно значению_2, в противном случае возвращает значение_1.
SELECT NULLIF("SQL Academy", "SQL Academy") AS sql_trainer;
-- nullОконные функции SQL
Мощный инструмент языка SQL, позволяющий проводить сложные вычисления по группам строк, которые связаны с текущей строкой.
SELECT <оконная_функция>(<поле_таблицы>)
OVER (
[PARTITION BY <столбцы_для_разделения>]
[ORDER BY <столбцы_для_сортировки>]
[ROWS|RANGE <определение_диапазона_строк>]
)- <оконная_функция>(<поле_таблицы>) — используемая оконная функция. Например AVG(price).
- Далее следует OVER, который определяет окно (группу строк), которое будет передаваться в оконную функцию. Если конструкцию OVER () оставить без параметров, то окном будет выступать вся таблица.
Далее внутри OVER следуют 3 необязательных параметра, с помощью которых можно гибко настраивать окно:
- с помощью PARTITION BY <столбцы_для_разделения> выборка делится на непересекающиеся подмножества, где каждое подмножество содержит строки с одинаковыми значениями в одном или нескольких столбцах, образуются партиции.
- с помощью ORDER BY <столбцы_для_сортировки> устанавливается порядок строк внутри окна, особо важную роль играет в оконных функциях ранжирования.
- с помощью ROWS|RANGE <определение_диапазона_строк> формируются диапазоны строк. С помощью этого параметра можно указать сколько строк брать до и после текущей в окно.
Для начала давайте получим список студентов и идентификатор класса, в котором они учатся:
SELECT
Student.first_name,
Student.last_name,
Student_in_class.class
FROM
Student_in_class
JOIN
Student ON Student_in_class.student = Student.id;А теперь, чтобы вычислить сколько учащихся учится в каждом из классов и вывести эту информацию в новую колонку, мы можем применить оконную функцию:
SELECT
Student.first_name,
Student.last_name,
Student_in_class.class,
COUNT(*) OVER (PARTITION BY Student_in_class.class) AS student_count_in_class
FROM
Student_in_class
JOIN
Student ON Student_in_class.student = Student.id;Выражение PARTITION BY Student_in_class.class разделяет все строки таблицы на партиции по полю class. Так, для каждой из строк в оконную функцию будут подаваться только те строки таблицы, где поле class совпадает с полем class в текущей строке.
Функция COUNT же возвращает количество переданных в неё строк, тем самым мы и получаем сколько учащихся учится в каждом из классов.
Партиции в оконных функциях
Для того, чтобы использовать партицию вместе с оконной функцией необходимо придерживаться следующего синтаксиса:
SELECT <оконная_функция>(<поле_таблицы>)
OVER (
PARTITION BY <столбцы_для_разделения>
)Каждая категория жилья имеет свои ценовые рамки. Чтобы узнать среднюю стоимость в конкретной категории и сравнить её с текущей, как раз можно использовать оконные функции.
SELECT
home_type, price,
AVG(price) OVER (PARTITION BY home_type) AS avg_price
FROM Rooms- PARTITION BY home_type делит все записи на разные партиции на основе уникальных значений столбца home_type
- затем, для каждой записи, AVG(price) вычисляет среднюю цену (price) в рамках её партиции (home_type)
Результатом выполнения этой части запроса будет столбец avg_price, в котором для каждой записи будет указано среднее значение цены для её категории жилья (home_type).
Партиции по нескольким колонками
SELECT
home_type, has_tv, price,
AVG(price) OVER (PARTITION BY home_type, has_tv) AS avg_price
FROM Rooms| home_type | has_tv | price | avg_price |
|---|---|---|---|
| Entire home/apt | 0 | 140 | 170 |
| Entire home/apt | 1 | 99 | 132.6667 |
Здесь PARTITION BY home_type, has_tv создаёт уникальные партиции для каждой комбинации home_type и has_tv, позволяя вычислить среднюю цену жилья для текущей категории жилья с наличием или без наличия телевизора.
Сортировка внутри окна (накопительный итог)
Сортировка в оконных функциях SQL — ключ к расширенному анализу данных. Она позволяет упорядочивать данные внутри определённой группы или окна, обеспечивая более точные и нацеленные агрегатные вычисления. Это особенно полезно при работе с временными рядами, где важен порядок событий, или при ранжировании данных внутри групп.
SELECT user_id,
start_date,
total AS reservation_price,
SUM(total) OVER (
PARTITION BY user_id
ORDER BY start_date
) AS cumulative_total
FROM Reservations;- Данные в рамках партиции стали отсортированы по дате начала бронирования
- Изменился способ подсчёта общей суммы затраченных средств: теперь сумма в рамках партиции накапливается, а не выводится как финальная. Это связано с одной особенностью использования сортировки без явного указания ROWS|RANGE в выражении OVER. На этом остановимся поподробнее.
Особенности использования сортировки без указания рамок окна
SELECT <оконная_функция>(<поле_таблицы>)
OVER (
[PARTITION BY <столбцы_для_разделения>]
[ORDER BY <столбцы_для_сортировки>]
[[ROWS или RANGE] <определение_диапазона_строк>]
)Помимо блока с PARTITION BY и ORDER BY в нем присутствует опциональный блок ROWS|RANGE, на нем мы остановимся детально в следующей статье, но сейчас важнее, то для чего он нужен. Он позволяет указать рамки окна относительно текущей строки, которые будут использоваться для вычисления в оконной функции.
Так, можно указать, чтобы при рассчитывании значений для текущей строки в оконную функцию отправились не все записи в рамках текущей партиции, а только N записей до текущей строки и N после.
При использовании ORDER BY, если в блоке ROWS|RANGE ничего не указано, то в оконной функции автоматически применяется правило RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW. Это означает, что окно будет начинаться с первой строки и заканчиваться текущей строкой.
Рамки окон
Используя синтаксис ROWS или RANGE мы можем определить какое именно окно с данными будет передаваться в оконную функцию для вычисления значения для текущей строки.
SELECT <оконная_функция>(<поле_таблицы>)
OVER (
...
[ROWS или RANGE] BETWEEN <начало границы окна> AND <конец границы окна>
)Например, если мы хотим, чтобы в оконную функцию при вычислениях попадали только две предыдущие записи и текущая строка, то синтаксис будет выглядеть следующим образом:
[ROWS или RANGE] BETWEEN 2 PRECEDING AND CURRENT ROWВозможные определения границ окна
- UNBOUNDED PRECEDING, все строки, предшествующие текущей
- N PRECEDING, N строк до текущей строки
- CURRENT ROW, текущая строка
- N FOLLOWING, N строк после текущей строки
- UNBOUNDED FOLLOWING, все последующие строки
Отличие ROWS от RANGE
ROWS работает с физическими строками
RANGE с значениями атрибута ( схоже с between )
Виды оконных функций
- Агрегатные оконные функции
- Ранжирующие оконные функции
- Оконные функции смещения
Агрегатные оконные функции
Агрегатные функции — это функции, которые выполняют на наборе данных арифметические вычисления и возвращают итоговое значение.
- SUM — подсчитывает общую сумму значений;
- COUNT — считает общее количество записей в колонке;
- AVG — рассчитывает среднее арифметическое;
- MAX — находит наибольшее значение;
- MIN — определяет наименьшее значение.
SELECT id,
home_type,
price,
SUM(price) OVER(PARTITION BY home_type) AS 'Sum',
COUNT(price) OVER(PARTITION BY home_type) AS 'Count',
AVG(price) OVER(PARTITION BY home_type) AS 'Avg',
MAX(price) OVER(PARTITION BY home_type) AS 'Max',
MIN(price) OVER(PARTITION BY home_type) AS 'Min'
FROM Rooms;Ранжирующие оконные функции
Ранжирующие оконные функции — это функции, которые ранжируют значение для каждой строки в окне.
В ранжирующих функциях под ключевым словом OVER обязательным идёт указание условия ORDER BY, по которому будет происходить сортировка ранжирования.
- ROW_NUMBER — возвращает номер строки, используется для нумерации;
- RANK — возвращает ранг каждой строки. Вот как это работает:
- Сортировка: во-первых, строки сортируются по одному или нескольким столбцам. Это столбцы указываются в ORDER BY в конструкции OVER.
- Присвоение рангов: каждой уникальной строке или группе строк, имеющих одинаковые значения в столбцах сортировки, присваивается ранг. Ранг начинается с 1.
- Одинаковые значения: если у нескольких строк одинаковые значения в столбцах сортировки, они получают одинаковый ранг. Например, если две строки занимают второе место, обе получают ранг 2.
- Пропуск рангов: после группы строк с одинаковым рангом, следующий ранг увеличивается на количество строк в этой группе. Например, если две строки имеют ранг 2, следующая строка получит ранг 4, а не 3.
- Продолжение сортировки: этот процесс продолжается до тех пор, пока не будут присвоены ранги всем строкам в наборе результатов.
- DENSE_RANK — возвращает ранг каждой строки. Но в отличие от функции RANK, она для одинаковых значений возвращает ранг, не пропуская следующий;
SELECT id,
home_type,
price,
ROW_NUMBER() OVER(PARTITION BY home_type ORDER BY price) AS 'row_number',
RANK() OVER(PARTITION BY home_type ORDER BY price) AS 'rank',
DENSE_RANK() OVER(PARTITION BY home_type ORDER BY price) AS 'dense_rank'
FROM Rooms;Оконные функции смещения
Оконные функции смещения — это функции, которые позволяют перемещаться и обращаться к разным строкам в окне, относительно текущей строки, а также обращаться к значениям в начале или в конце окна.
- LAG — обращается к данным из предыдущих строк окна.Имеет три аргумента: столбец, значение которого необходимо вернуть, количество строк для смещения (по-умолчанию 1), значение, которое необходимо вернуть, если после смещения возвращается значение NULL.
- LEAD — обращается к данным из следующих строк. Аналогично LAG имеет 3 аргумента.
- FIRST_VALUE — возвращает первое значение в окне. В качестве аргумента принимает столбец, значение которого необходимо вернуть.
- LAST_VALUE — возвращает последнее значение в окне. В качестве аргумента принимает столбец, значение которого необходимо вернуть
SELECT id,
home_type,
price,
LAG(price) OVER(PARTITION BY home_type ORDER BY price) AS 'lag',
LAG(price, 2) OVER(PARTITION BY home_type ORDER BY price) AS 'lag_2',
LEAD(price) OVER(PARTITION BY home_type ORDER BY price) AS 'lead',
FIRST_VALUE(price) OVER(PARTITION BY home_type ORDER BY price) AS 'first_value',
LAST_VALUE(price) OVER(PARTITION BY home_type ORDER BY price) AS 'last_value'
FROM Rooms;ДЛЯ ПРИМЕРА
найти разницу во времени между вылетами среди рейсов одной компании.
SELECT
company,
CAST(time_out AS TIME) AS time_out,
TIMEDIFF(
time_out,
FIRST_VALUE(time_out) OVER (
PARTITION BY company
ORDER BY time_out
ROWS 1 PRECEDING
)
) AS time_diff
FROM TripPIVOT и UNPIVOT
PIVOT – это оператор Transact-SQL, который поворачивает результирующий набор данных, т.е. происходит транспонирование таблицы, при этом используются агрегатные функции, и данные соответственно группируются. Другими словами, значения, которые расположены по вертикали, мы выстраиваем по горизонтали.
SELECT столбец для группировки, [значения по горизонтали],…
FROM таблица или подзапрос
PIVOT(агрегатная функция
FOR столбец, содержащий значения, которые станут именами столбцов
IN ([значения по горизонтали],…)
) AS псевдоним таблицы (обязательно)
в случае необходимости ORDER BY;
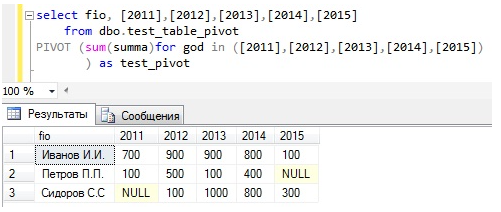
- fio — столбец, по которому мы будем осуществлять группировку;
- [2011],[2012],[2013],[2014],[2015] — названия наших столбцов по горизонтали, ими выступают значения из колонки god;
- sum(summa) — агрегатная функция по столбцу summa;
- for god in ([2011],[2012],[2013],[2014],[2015]) — тут мы указываем колонку, в которой содержатся значения, которые будут выступать в качестве названия наших результирующих столбцов, по факту в скобках мы указываем то же самое, что и чуть выше в select;
- as test_pivot — это обязательный псевдоним, не забывайте его указывать, иначе будет ошибка.
UNPIVOT – это оператор Transact-SQL, который выполняет действия, обратные PIVOT. Сразу скажу, что да он разворачивает таблицу в обратную сторону, но в отличие от оператора PIVOT он ничего не агрегирует и уж тем более не раз агрегирует.
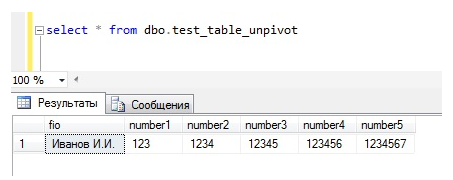
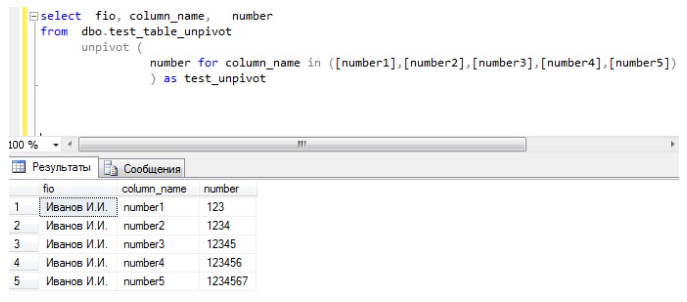
Рекурсивные запросы
Рекурсивные запросы используют в подзапросе данные самого себя.
Используют их чаше всего для построения иерархий данных. Например, для сотрудника вывести список его подчиненных, для этих подчиненных список их подчиненных и т.д.
Рекурсивный подзапрос состоит из двух частей: нерекурсивной, определяющей первоначальный набор данных, и рекурсивной части, выполняющейся итерационно (несколько раз). Нерекурсивная и рекурсивная части разделяются UNION или UNION ALL.
WITH RECURSIVE lv_recursive (num) as (
-- Нерекурсивная часть
SELECT 1 AS num
UNION ALL
-- Рекурсивная часть
SELECT p.num + 1
FROM lv_recursive p
WHERE p.num < 3
)| # | num |
|---|---|
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
Результат рекурсивного подзапроса определяется следующим образом:
- Выполняется нерекурсивная часть подзапроса. Ее результат добавляется в общий результат подзапроса и временную таблицу, для строк которой нужно выполнить рекурсивную часть.
- Выполняется рекурсивная часть подзапроса. Вместо таблицы во фразе
FROMс названием рекурсивного подзапроса (lv_recursiveв нашем случае), используются строки из временной таблицы. Результат рекурсивной части добавляется в общий результат подзапроса и становится содержимым временной таблицы. Таким образом, на следующей итерации рекурсивный запрос выполняется для строк, полученных на текущей. - Если во временной таблице есть записи, то переходим к шагу 2. Если нет — то рекурсивный подзапрос выполнен.
WITH RECURSIVE lv_initial AS (
SELECT 100 AS start_number,
4 AS count_iterations
UNION ALL
SELECT 200 AS start_number,
2 AS count_iterations
),
lv_numbers (start_number, count_iterations, current_iteration, result_number) AS (
SELECT start_number,
count_iterations,
1 AS current_iteration,
start_number AS result_number
FROM lv_initial
UNION ALL
SELECT p.start_number,
p.count_iterations,
p.current_iteration + 1,
p.result_number + 1
FROM lv_numbers p
WHERE p.current_iteration < p.count_iterations
)
SELECT n.start_number,
n.result_number
FROM lv_numbers n
ORDER BY n.start_number,
n.result_number
https://learndb.ru/articles/article/91
Генераторы последовательностей (SEQUENCE)
Последовательность CREATE SEQUENCE – это объект базы данных, который генерирует целые числа в соответствии с правилами, установленными во время его создания. Для последовательности можно указывать как положительные, так и отрицательные целые числа. В системах баз данных последовательности применяют для самых разных целей, но в основном для автоматической генерации первичных ключей. Тем не менее к первичному ключу таблицы последовательность никак не привязана, так что в некотором смысле она является еще и объектом коллективного пользования. Если первичный ключ нужен лишь для обеспечения уникальности, а не для того, чтобы нести определенный смысл, последовательность является отличным средством. Последовательность создается командой CREATE SEQUENCE.
CREATE SEQUENCE supplier_seq
MINVALUE 1
MAXVALUE 999999999999999999999999999
START WITH 1
INCREMENT BY 1
CACHE 20;
supplier_seq.NEXTVAL; -следующее значениеНедостатком создания последовательности с cache, что если происходит отказ системы, все кэшированные значения последовательности, которые не были использованы, будут утеряны. Это приведет к разрывам в значениях, назначенной последовательности. Когда в система восстановится, Oracle будет кэшировать новые номера, с того места, где была прервана последовательность, игнорируя утерянные значения последовательности.
Подробно